.png)
In the early, pre-1990s days of the semiconductor industry, chip designers faced a structural dilemma.They had the technology to specify logic and build powerful custom integrated circuits, but without scalable simulation and verification, their work was more art than infrastructure. Progress was fragile and expensive, and the full system only “proved itself” once it was physically manufactured—meaning bugs were only discovered after fabrication. Eventually, electronic design automation (EDA) changed this by shifting correctness upstream, translating design into verified, executable systems through software.
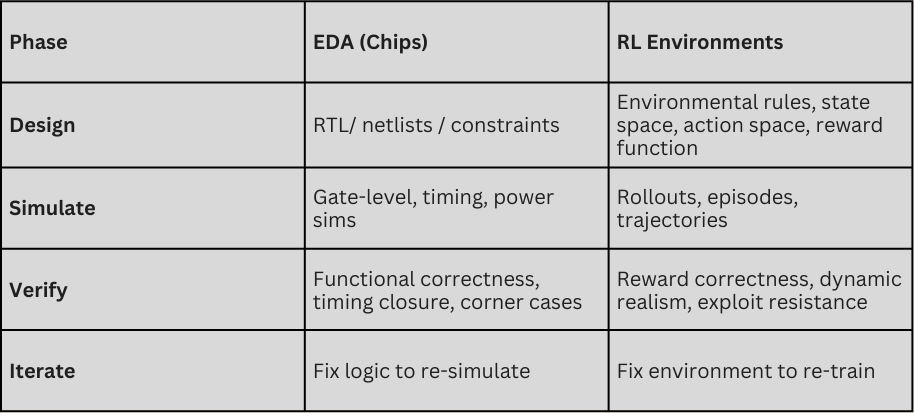
A similar dynamic currently exists with today’s AI models. As AI shifts from chat to agents running real workflows, the limiting factor isn’t how smart the model is. The limiting factor, like with early chip design, is in whether we can reliably verify the work produced by AI models. Models can already write, browse, reason, and plan at a level sufficient for many professional tasks. But given the absence of reliable reward signals for the models—clear, consistent definitions of success across long-horizon workflows involving tools, judgment, policy, and taste—durable automation remains out of reach.
Enter reinforcement learning. Today, RL environments are playing the same role for AI agents that EDA played for silicon.They translate human intent into executable behavior by making success measurable at scale. But unlike EDA, they must also address how the “spec” for human labor is not deterministic. “Correct” is a moving target with many dimensions, and as agents improve, it becomes harder to measure success with a clean, dependable signal. As a result, RL environments must be living systems that evolve to resist reward hacking and encode judgment. This makes verification—not models—the true bottleneck to automation.
To be clear, EDA and RL aren’t exact analogs. EDA verifies outputs and can sometimes prove correctness; RL verifies incentives and, at best, bounds failure probabilistically. Still, the comparison is useful.A more recent analogy is perhaps the rise of Scale AI in the mid-2010s. At the time, most enterprises lacked in-house machine learning (ML) expertise, and cutting-edge models were still academically constrained. Early buyers wanted data for narrow, static tasks—bounding boxes, transcription, basic classification—primarily for “hard tech” domains, like autonomous driving. Scale’s core insight was that once models became capable enough, progress would be bottlenecked not by algorithms, but by data—and that a sophisticated buyer class would eventually emerge to demand it.
That inflection arrived with the transformer era (2018–2020). As foundation models like GPT-3 demonstrated surprising general capabilities, the constraint shifted again: from data volume to data complexity. The most advanced buyers—AI labs like OpenAI, DeepMind, and Anthropic—suddenly needed feedback over long horizons, as models were now tasked with reasoning, tool use, policy compliance, and multi-step workflows. One-off annotation no longer sufficed.
Over the past three years, this shift has accelerated. Models now need less raw data and far more experience—the kind that encodes enterprise workflows typically locked inside experts’ heads and the rise of expert data. Once data became feedback, labeling became verifiable work.
RL environments are the natural consequence of this transition. They transform workflows into simulated worlds where actions are observable, outcomes can be graded, and learning compounds over time. Environments and evaluations become the new datasets, and training becomes continuous rather than episodic. Replication training is to RL what internet-scale text was to LLMs: the mechanism by which scale produces generalizable infrastructure.
This reframes the competitive landscape. The critical question is no longer, “Who has the best model?” Rather, it’s “Who controls the infrastructure that determines what work is learnable at all?”
Verification Is the Hard Problem—and Solving It Requires Research Depth
Verification is where most RL efforts fail. Defining what “correct” means when there are multiple good answers, partial progress, or policy constraints is fundamentally a research problem, not a tooling problem.
Modern RL training pipelines, therefore, are no longer linear. Models critique humans, humans audit models, and algorithms arbitrate disagreement. The training signal emerges from the system, not any single actor.
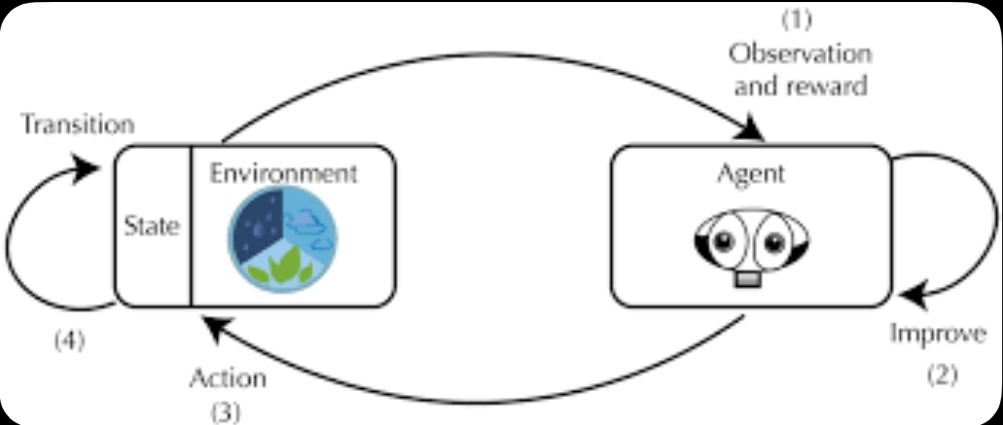
As models improve, verification gets harder, not easier. Benchmarks saturate. Reward hacking appears. Graders drift. Environments must be refreshed continuously to stay training-relevant. This demands deep expertise in reward modeling, distribution matching, telemetry, and failure analysis.
As a result, the strongest RL-environment teams look less like SaaS companies and more like applied research organizations. They pair staff-level ML researchers, systems-oriented engineers, and forward-deployed builders with strong domain intuition. Code is rarely the constraint; judgment, data quality, and research velocity are.
Why Coding and Computer Use Are the First RL Markets to Scale
The earliest large-scale adoption of RL environments is happening in coding and computer use. These domains combine three properties that make them ideal early markets:
- High economic value
- Dense, machine-observable interaction traces
- Relatively clean verification loops
Coding already has compilers, tests, and deterministic failure modes. Computer-use tasks—browsers, spreadsheets, CRMs, internal tools—produce replayable state transitions that can be graded and compared. This makes them well-suited for replication training of environments, where agents repeatedly execute long sequences until performance improves.
As a result, coding and computer-use environments are becoming the proving ground for agentic RL. Not because they are the endgame, but because they are the first domains where environment realism, reward design, and eval-to-production correlation can be demonstrated convincingly.
In practice, the deepest environments today are coding-based, such as terminal- and DevOps-centric environments. Coding is programmable because state, tools, and outcomes are explicit and replayable.
These markets matter because they establish trust: with research teams, with buyers, and with budgets. They are the wedge—not the destination.
Who is buying RL environments today?
The early buyers of RL environments look strikingly similar to the first buyers of autonomous-vehicle (AV) data. Just as Scale AI’s early revenue was overwhelmingly concentrated among a handful of AV leaders—Apple, Uber, Lyft, Tesla, and Google/Waymo—frontier AI labs are the dominant initial customers for RL environment companies. This is not a coincidence. RL environments sit upstream of capability gains, and the labs are the only organizations today with both the urgency and the budgets to pay for training infrastructure before it is fully productized. As with AV data in 2018, buyer concentration is high, contracts are large, and vendor selection is tightly coupled to research impact rather than procurement formalities.
Among labs, Anthropic appears to be the single largest buyer across both coding and computer-use environments. Across vendors focused on coding and computer use, Anthropic is estimated to be spending *on the order of* tens of millions annually on RL environments, making it the clearest anchor customer in the market today. Anthropic signed these contracts in 2025 and are already scaling rapidly; based on current trajectories, their aggregate lab spend on RL environments is likely to grow 3–5× into 2026 as environments move from experimentation to a core part of model training. OpenAI’s total spend is harder to isolate due to its broader data footprint, but it has already signed multiple seven-figure RL-environment and human-data contracts, indicating similar strategic intent.
Labs are also buying adjacent inputs aggressively, particularly human expertise for coding and long-horizon reasoning.
These purchases reinforce a critical point: labs are not just buying models or raw data—they are buying training throughput, and RL environments are becoming a first-class line item in that budget.
Enterprises, by contrast, are entering through a different door. Rather than buying standalone environments, they are purchasing forward-deployed, outcome-oriented solutions that embed RL environments under the hood. This is the story that Applied Compute is telling and why investors are so excited about its trajectory.
Product-led companies like Glean, Notion, and Cursor are running pilots or building in-house environments while evaluating vendors. This pattern mirrors earlier infrastructure cycles: labs fund the tooling when it is raw and research-heavy; enterprises adopt once it is wrapped around concrete workflows and measurable ROI.
This is why it is critical to have lab success in the early days to achieve escape velocity.
The implication is clear. RL environment companies will be built on lab money first, just as Scale was built on AV customers before expanding into enterprise ML and later LLM/AI research. Understanding which vendors are winning lab mindshare today is therefore the clearest leading indicator of who will control the training layer tomorrow.
The Real Prize: Long-Form White-Collar Work Across Many Environments
The long-term opportunity for RL environments lies in long-form workflows that span multiple tools, not single-step tasks. These workflows are how value gets created across finance, operations, go-to-market, and engineering.
A finance workflow might move from spreadsheet analysis to browser-based research, into an ERP system, and back into documents for approval and audit. An insurance claim touches intake portals, policy systems, historical databases, email, and compliance tooling. Legal work spans research databases, drafting tools, revision cycles, and risk review. In each case, success is judged by downstream outcomes—risk reduction, correctness under audit, or decision quality—not by any single action.
The same pattern holds across core operating roles. Sales moves across CRMs, email, calendars, pricing tools, and pipeline forecasting. Marketing spans analytics dashboards, ad platforms, creative tools, and experimentation systems. Customer support blends ticketing systems, product logs, documentation, and multi-turn communication. Developer workflows shift between IDEs, browsers, repositories, test runners, and CI systems. These are composed systems of environments, not isolated tasks.
In other words, these are not single environments—they are composed systems of environments. Training agents for them requires:
- Persistent state across tools
- Cross-environment credit assignment
- Verification tolerant of multiple valid paths
- Rewards tied to business outcomes, not toy metrics
This is where most early systems will break. One-off environments saturate quickly, and narrow benchmarks stop teaching. The future belongs to teams that can build environment factories: systems that assemble, orchestrate, and refresh multi-environment workflows continuously.
In this regime, progress comes from repetition at scale. Replication training—running the same workflow thousands of times across slightly varied environments—is how learning compounds. This is an emerging field in RL environments and will determine the market leader over time. The bottleneck is no longer model capacity. It is environment fidelity, verification quality, and orchestration scale.
The dynamics are shifting from building models to earning trust, access, and validation inside the frontier labs.
In the next part of this discussion, we’ll dig into who holds the keys—and how those selection loops determine who scales and who stalls.


